
What Is Citation Verification for AI Content?
Citation verification for AI content is the operational process of confirming that every statistic, claim, and source reference in an AI-generated article traces to a real, retrievable document — before that content is published. Without it, multi-location operators scaling to 20-50+ articles per month are one fabricated citation away from a compliance incident.
“Vibe citing is when AI language models generate academic citations without verifying the referenced works actually exist… These aren’t minor formatting errors — they’re wholesale inventions that happen to look syntactically correct.” — SoftwareSeni.
Content Ops Lab built citation verification into its production infrastructure from day one — 1,000+ articles and pages delivered across a 23-month engagement in a regulated healthcare environment with zero compliance violations.
Related: The AI Citation Economy – Why Visibility Matters More Than Rankings
Why Does AI-Generated Content Produce Fabricated Citations at Scale?
AI-generated content produces fabricated citations because large language models are designed to predict the most statistically plausible text sequence—not to verify factual accuracy. At low volume, fabrication is manageable. At scale, it is a structural production failure.
The Mechanics of Citation Hallucination
AI models don’t “look up” sources when they write. They generate text that resembles a citation because citations follow predictable syntactic patterns — author names, publication years, journal titles, volume numbers.
- Pattern-matching produces syntactically correct but factually empty references
- Author names, DOIs, and journal titles are commonly fabricated as a set
- The output looks credible because the format is right, even when the source doesn’t exist
- Real and fabricated citations appear identical to the human eye without verification
Research analyzing 2.2 million citations from 56,381 papers at top-tier AI/ML venues confirmed that 1.07% of papers contain invalid or fabricated citations, with an 80.9% increase in invalid citations in 2025 alone — arXiv (GhostCite/CiteVerifier). The failure rate is increasing in direct proportion to the volume of AI content.
How Volume Accelerates the Failure Mode
At 4-8 articles per month, one fabricated citation is a manageable editorial problem. At 20-50+ articles per month, it becomes a systemic risk.
- A 2% fabrication rate at 50 articles/month means one bad citation per week
- Multi-location operations multiply that risk across location-specific pages
- A single unverified statistic in a location page template can propagate across dozens of URLs simultaneously
- Compliance departments don’t distinguish between “one bad article” and “pattern of unverified content”
Volume is the accelerant. The same hallucination rate that’s invisible at the small scale becomes a liability exposure at the production scale.
What Operators Can’t Catch Manually
Manual spot-checking creates a false sense of security. Independent verification of every source reference — tracking down original papers, checking DOIs, confirming author lists — cannot keep pace with the velocity of AI output.
- Hallucinated citations are often disguised among correct ones, making manual verification labor-intensive — arXiv (HalluCiteChecker)
- A reviewer catching one fabricated citation has no mechanism to confirm the remaining four are real
- Non-resolving URLs are particularly difficult to catch — broken links may indicate fabrication or link rot
- Manual check capacity cannot scale to match the AI content output velocity
The volume that makes AI content economically viable is the same volume that makes manual verification structurally impossible.
What Breaks When Citation Failures Reach a Multi-Location Content Operation?
Citation failures in a multi-location operation create three distinct failure modes: regulatory exposure, brand trust erosion, and compounding content debt. Each is serious independently. Together, they represent the operational case for treating citation verification as infrastructure.
Compliance Exposure Across Regulated Industries
Healthcare, legal, and financial content are subject to regulatory frameworks that apply regardless of whether a human or an AI produces the output. The tool used to generate content does not change the operator’s compliance obligation.
- Healthcare content citing fabricated NIH statistics creates direct liability under FTC and state advertising standards
- Legal content referencing non-existent case law has produced court sanctions against attorneys submitting AI-generated briefs
- Financial content with hallucinated data triggers FINRA Rule 2210, which governs all public-facing communications regardless of how they were created — Stagg Wabnik Law Group
- A single compliance incident in a regulated industry can trigger a review of an entire content archive
Multi-location operators face an amplified version of this risk — content published across 10+ location pages carries 10+ instances of the same compliance exposure.
Brand Trust Erosion at Scale
Fabricated citations aren’t just a legal risk — they’re a credibility problem that compounds over time.
- One documented fabrication signals a systemic absence of verification controls
- Patients, clients, and partners in regulated industries have elevated trust thresholds — a single incident can redefine authority positioning
- Content published under a brand name carries that brand’s credibility, regardless of how it was produced
- At 50 articles per month, brand trust exposure scales proportionally with output volume
The cost of a trust incident is not recoverable through a retraction. It requires sustained production of verified content to rebuild authority.
The Hidden Cost of Unverified Output
Beyond compliance and brand trust, unverified AI content creates a less visible but equally significant problem: content debt.
- Hallucinated URL rates range from 3% to 13%, with 5–18% of URLs non-resolving overall — arXiv (URL Health Study)
- A content archive built on unverified citations requires full re-verification before it can serve as a credible AI search reference base
- Every article published without verification is a future editorial liability, not a sunk content cost
The operational math is straightforward: prevention is a workflow step. Remediation is a project.
What Do Current Options for AI Content Production Actually Offer on Verification?
Most content production options treat citation verification as a formatting step at the end of the process rather than as a structural control built into the workflow. Each approach has genuine strengths. None of them solves the verification problem at scale.
Internal Teams and the Capacity Gap
Internal teams have the contextual knowledge, brand familiarity, and editorial judgment that external providers can’t replicate quickly. Manual verification is feasible at low volume.
- Deep brand voice and subject matter expertise without ramp-up time
- Direct access to subject matter experts for original knowledge integration
- Full editorial control over compliance-sensitive content decisions
- Manual verification is feasible at low volume
Most internal marketing teams hit a production wall at 8-12 articles per month, and verification is the first thing to compress under deadline pressure.
Traditional Agencies and the Verification Gap
Traditional agencies offer production scale, but verification infrastructure is not part of a standard agency workflow.
- Agency pricing at $300-500 per article is built around writing efficiency, not verification infrastructure
- Template-driven workflows optimize for consistent output format, not evidence chain integrity
- Agency writers have no structural mechanism to cross-check sources at line-number granularity
- Compliance standards in regulated industries require verification protocols that standard agency models don’t include
Scale without verification is not a content operation. It’s a fabrication distribution system.
Generic AI Tools and the Zero-Assumption Problem
Platforms like ChatGPT, Claude, and Gemini generate well-structured content at volume. They are not citation verification systems.
- AI tools generate citations based on training data patterns, not live database retrieval
- No major AI content platform includes zero-assumption verification by default
- The operator bears compliance responsibility for every citation that ships under their brand name
- AI-generated content without verification requires the same editorial scrutiny as human-written content with fabrication tendencies
The issue isn’t AI content itself. It’s AI content without a verification control system running alongside it.
If your operation is scaling AI content without a citation verification workflow in place, that gap is already a compliance exposure. Contact us to discuss what systematic verification looks like for your content operation.
How Does Citation Verification for AI Content Actually Work Inside a Production Operation?
A citation verification system functions as an external audit layer running parallel to content generation — not as a final edit, but as a structural control that validates every evidence claim before content publishes. The core principle is zero-assumption: every citation is treated as potentially fabricated until confirmed against source material.
Research-First Protocol Before Generation
Verification is structurally impossible if no verified source material exists before AI generation begins. The research-first protocol inverts the standard production sequence.
- Research from credible sources is compiled before any AI generation begins
- Source documents are stored with metadata: title, URL, publication date, line reference
- AI generation is constrained to content traceable back to the pre-verified research file
- No article advances unless source research exists and is accessible for cross-check
When generation is constrained to verified source material, the model cannot invent a citation for a source that isn’t in the research file.
Line-by-Line Cross-Check Infrastructure
Research-first removes the fabrication opportunity. Line-by-line cross-checking confirms the generated content actually reflects the source it claims to represent.
- Every statistic and claim in a draft is traced back to a specific line in the source research document
- Exact quotes are extracted — paraphrasing is not permitted because it introduces interpretation risk
- Each citation is tagged with source name, URL, and line number before the article advances
- The verification creates an audit trail: any citation in the published article can be traced to its original source
Adding statistics to content improves AI visibility by 41% — the single most effective optimization technique tested — ZipTie (citing Princeton/Georgia Tech study). Verification isn’t just a compliance control — it’s the mechanism that makes citations useful for AI search visibility.
STAT vs. CLAIM Labeling as Audit Architecture
Not all citations carry equal evidentiary weight. The STAT vs. CLAIM labeling system creates differentiated verification standards for different evidence types.
- [STAT]: Citations containing numerical data — percentages, counts, rates — requiring confirmed source metadata and exact figure match
- [CLAIM]: Sourced statements without numerical data — assertions, definitions, regulatory positions — requiring source existence confirmation and semantic alignment
- Labels are applied at the research extraction stage and retained through publication
- The labeling creates an audit trail that allows any compliance reviewer to identify the evidence type and verification standard applied to each citation
The labeling system answers the question every compliance review eventually asks: how do you know this is accurate?
Related: Structured Content for AI Search – How It Gets You Cited by AI
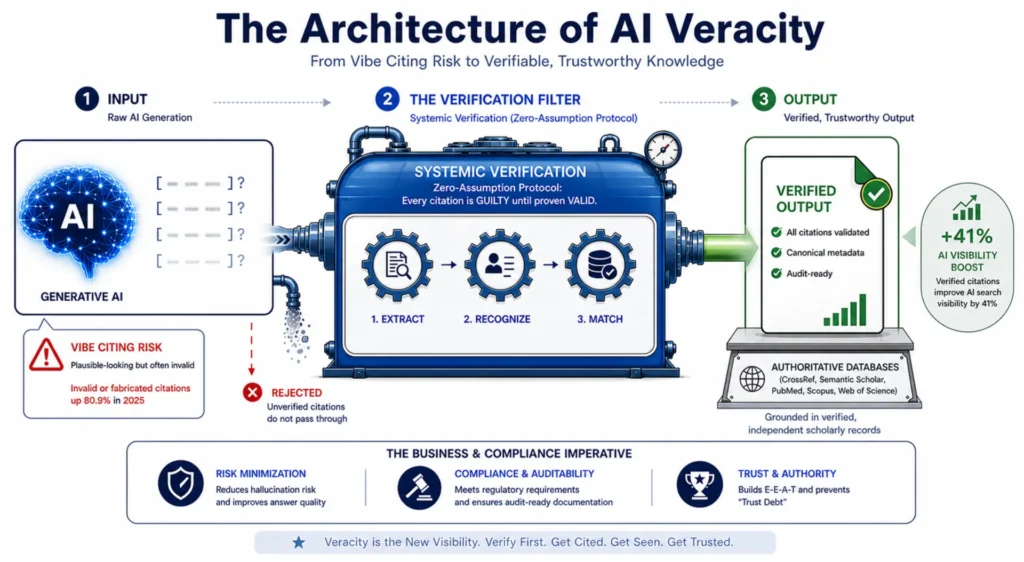
What Does Citation Verification for AI Content Actually Deliver in Production?
Citation verification is not just a risk mitigation tool. It is a production investment with measurable returns in AI search visibility, conversion performance, and competitive positioning.
AI Search Visibility Gains from Verified Citations
AI engines operate as risk-minimizing systems. “AI citation selection is driven by risk minimization, not relevance ranking… AI engines ask a fundamentally different question: ‘what’s the safest thing I can repeat without being wrong?'” — ZipTie
- Adding authoritative citations and statistics more than doubled visibility scores in GEO research — pushing unoptimized content from 19.3 to above 40 in measured visibility metrics
- Only 12% of AI-cited links rank in Google’s top 10 — 88% of AI citations come from content layers that traditional SEO tools don’t monitor
- Topical authority (r=0.41) is a significantly stronger predictor of AI citations than domain authority (r=0.18)
The visibility premium for verified, citation-rich content is measurable and growing as AI platforms capture a larger share of search volume.
Conversion Performance of Citation-Worthy Content
The verification infrastructure that makes content citation-worthy is also the one that makes it authoritative enough to close the trust gap at conversion.
- In a 23-month regulated healthcare production engagement, AI search traffic converted at 21.4% average vs. 3.32% site baseline — a 6.4x performance multiplier
- 95+ confirmed conversions from AI search platforms over an 8-month measurement window
- ChatGPT referral traffic reached a 40% peak CVR — from a channel representing less than 0.3% of total traffic
- 887% ChatGPT session growth over 7 months, driven by content architecture that AI systems could extract and cite with confidence
The content AI systems cite is what makes it credible. The conversion premium follows directly.
Compliance Record as Competitive Differentiation
In regulated industries, a documented compliance record is a competitive differentiator—not just a risk-management asset.
- Zero compliance incidents creates a defensible production record for legal, regulatory, and enterprise procurement review
- Operators expanding into new markets can apply the same verification infrastructure without restarting compliance protocols
- A verified content archive is a compounding asset — each piece strengthens the topical authority and citation credibility of the entire domain
Consistently verified at scale, a competitive position is difficult to replicate quickly.
Is Your Current Content Operation Built for Verification at Scale?
Most content operations were designed to produce content at the lowest cost per article — functional when search engines rewarded volume, but structurally inadequate when AI systems are the primary decision-makers in citation.
Signs Your Production System Has a Verification Gap
A verification gap doesn’t announce itself as a compliance incident. It presents as operational patterns that feel manageable individually.
- Writers are sourcing statistics through general web searches rather than pre-verified research documents
- Citations are added as a final formatting step rather than extracted from source files before generation
- No systematic distinction exists between numerical statistics and sourced assertions
- Published articles cannot be audited back to original source documents at line-number granularity
“The traditional ‘trust but verify’ methodology, long sufficient for conventional research tools, has proven inadequate for AI hallucinations and fabricated content. Legal practitioners are now embracing a more rigorous do not trust until verified’ standard — Thomson Reuters. The legal profession’s standard is a leading indicator. Regulated industries follow.
Done-For-You vs. System Build for Regulated Industries
Content Ops Lab offers two engagement models. The right choice depends on whether your organization wants to operate the verification infrastructure internally or outsource production entirely.
- Done-For-You: COL runs the complete production system — research, generation, verification, optimization, and delivery. Full verification infrastructure without internal headcount
- System Build: COL builds the complete verification infrastructure, trains your team to operate it, and delivers a single unified production system that your organization owns
- Both models deliver the same citation verification standard — STAT/CLAIM labeling, line-number audit trails, research-first protocols
- Regulated industries requiring internal control typically prioritize System Build; operators maximizing production velocity without adding headcount typically prioritize Done-For-You
The model is a capacity-and-control decision. The verification standard doesn’t change based on who operates the system.
What Operators Who Implement This Get Right
The operators who build citation verification into production infrastructure before they need it treat content compliance the same way they treat financial compliance — as a system requirement, not an editorial preference.
- They require research files to exist before generation begins, not after
- They define what “verified” means for their regulatory environment before the first article ships
- They build audit trails that survive a compliance review, not just an editorial review
- They measure content ROI in conversion and citation performance, not just publication volume
The competitive window for AI search citation dominance is measured in quarters. Operators building verification infrastructure now are establishing citation patterns that AI systems will reinforce over time.
How Content Ops Lab Builds Content Infrastructure
Over a 23-month production engagement inside a regulated healthcare organization, Content Ops Lab delivered 1,000+ citation-verified articles and pages with zero compliance violations — produced by verification infrastructure built into every stage of the workflow, not added as a final edit.
- 23-month production test inside a 12-location regulated healthcare organization
- 1,000+ citation-verified articles delivered — zero compliance violations across the full engagement
- 45% of all leads generated from organic search — outperforming paid search nearly 2:1
- AI search converting at 21.4% average vs. 3.32% site baseline — 6.4x performance multiplier
- 887% ChatGPT traffic growth in 7 months (July 2025–February 2026)
- 653% impression growth, 1,700% click growth for an emerging brand built from near-zero organic presence
- 5x production scale achieved — from 10 articles/month to 50+ without adding headcount
- Dual-brand methodology validated on both mature brand maintenance and aggressive growth scaling
The Content Ops Lab Production System
Every engagement runs the same four-stage workflow — verified at each stage, not audited at the end.
- Research: Credible sources verified and documented before AI generation begins — no writing from memory
- Verification: Line-by-line citation cross-check with STAT vs. CLAIM labeling and full audit trail per article
- Optimization: Multi-platform build — Google, ChatGPT, Perplexity, Claude, and Gemini simultaneously
- Delivery: WordPress staging or Google Docs — publish-ready, Grammarly-reviewed, compliance-grade
Verification isn’t a final edit in this system — it’s the condition that makes every subsequent stage defensible.
Ready to build content infrastructure with citation verification at its core? Get in touch today — we’ll assess your current production operation and outline what a systematic verification approach would look like for your organization.
FAQs About Citation Verification for AI Content
Can’t we just spot-check citations manually instead of building a citation verification system for AI content?
Spot-checking doesn’t scale and doesn’t solve the structural problem. Hallucinated citations are often embedded among correct ones, making random sampling unreliable. A content operation producing 20-50+ articles per month needs verification built into the workflow — research-first sourcing, line-number audit trails, STAT vs. CLAIM labeling — not a final-stage review that assumes most citations are accurate.
How long does it take to implement a citation verification workflow into an existing content operation?
A System Build engagement runs 12 weeks from discovery to full implementation. Most clients are producing verified content at full volume within 90 days of engagement start, with 90-day post-launch support to refine the workflow.
What specific regulatory risk does unverified AI content create in healthcare or legal content programs?
In healthcare, fabricated statistics can trigger violations of FTC advertising standards and scrutiny by state medical boards. In legal, attorneys have faced court sanctions for submitting briefs with AI-generated citations referencing non-existent cases. In financial services, FINRA Rule 2210 applies to all public-facing communications, regardless of how they were created — AI authorship is not a compliance exemption.
How is citation verification for AI content different from what a standard content agency delivers?
A standard agency delivers content optimized for readability and keyword performance — citation verification is not part of that workflow. Tracing every statistic back to a specific line in a verified source document requires pre-production research infrastructure, line-number documentation, and STAT vs. CLAIM classification that standard agency models don’t include.
Does Content Ops Lab handle citation verification in both its Done-For-You and System Build engagements?
Yes. Both models deliver the same standard — research-first sourcing, line-by-line cross-checking, STAT vs. CLAIM labeling, and audit trail documentation per article. In Done-For-You, COL runs the full verification workflow as part of managed production. In System Build, COL builds the infrastructure and trains your team to operate it.
Key Takeaways
- Citation verification for AI content is a structural production control — every statistic and claim requires traceable source confirmation before publication
- AI content hallucination rates are accelerating: research confirms an 80.9% increase in fabricated citations at top-tier academic venues in 2025 alone
- Manual spot-checking cannot scale to match AI content output velocity — verification must be built into the workflow at the research stage
- Verified content directly improves AI search visibility: adding statistics and authoritative citations has been shown to more than double content visibility scores in AI search environments
- In a 23-month regulated production engagement, citation verification enabled 1,000+ articles with zero compliance violations — while AI search traffic converted at 6.4x the site baseline
- The “do not trust until verified” standard now adopted by legal practitioners is a leading indicator for regulated industries broadly
- Operators building citation verification infrastructure now are establishing AI citation patterns that compound over time — the competitive window is measured in quarters, not years
Build Content Infrastructure That Compounds: Citation Verification for AI Content
Citation verification for AI content is not a technical refinement for the distant future — it is the production requirement that separates compliant, citation-worthy content from a library of liabilities accumulating at scale.
Research confirms fabrication rates are accelerating — an 80.9% increase in invalid citations at top-tier AI/ML venues in 2025 alone — arXiv (GhostCite/CiteVerifier). Adding statistics and authoritative citations more than doubles visibility in AI search environments.
The operators capturing that visibility premium built verification into their production system before they needed it — not after a compliance incident forced a content audit.
Content Ops Lab has operated that system at scale in a regulated healthcare environment for 23 months, with a documented compliance record. The infrastructure is proven. The window for first-mover advantage in AI search citations is open now — and it won’t stay that way.
Related: Generative Engine Optimization – How Brands Get Recommended by AI