
How to Verify AI Content Sources
Knowing how to verify AI content sources is the single most important operational decision a multi-location marketing team can make before scaling AI-assisted production. Because unverified AI content doesn’t just underperform, it creates liability. “A 2026 benchmark across 37 models reported hallucination rates between 15% and 52%” —SQ Magazine.
For regulated industries, that range isn’t a performance gap — it’s a compliance exposure window that widens with every article you publish. Most operators discover this after a fabricated statistic ships to a dozen location pages simultaneously.
Content Ops Lab built its verification infrastructure inside a 12-location regulated healthcare organization — 1,000+ articles delivered with zero compliance violations over 23 months.
Related: Content at Scale – Why Volume Without Verification Fails in AI Search
Why Does Unverified AI Content Create Liability for Multi-Location Operations?
Unverified AI content creates liability because multi-location publishing amplifies every error across your entire footprint simultaneously. A single hallucinated statistic propagates across every location article that shares the same content template, creating compliance exposure that scales with your operation.
The Financial Cost of Fabrication at Scale
The business case for verification infrastructure is no longer theoretical. “Global business losses from AI hallucinations reached $67.4 billion in 2024 alone” — SuprMind AI.
- $67.4B in global hallucination losses in 2024
- Regulated industries face direct regulatory sanctions, not just reputational damage
- Content production costs are recoverable; compliance violations often aren’t
For a VP of Marketing signing off on 40+ articles per month, the liability question isn’t hypothetical. It’s a number attached to every unverified publication.
How Hallucinations Cascade Across Location Pages
Multi-location content operations run on templates — and that efficiency is also their vulnerability. When a fabricated statistic enters a templated workflow, it replicates before human review catches it.
- One hallucinated claim can appear across 5, 10, or 50 location pages
- Template-driven production accelerates error propagation, not just content production
- Healthcare and legal content errors compound — incorrect claims carry direct exposure
The architecture that makes multi-location production efficient is also the one that makes verification non-negotiable.
Where Internal Review Processes Break Down
Most organizations assume human review catches fabrications. “Models were 34% more likely to use phrases like ‘definitely,’ ‘certainly,’ and ‘without doubt’ when generating incorrect information — making confident fabrications harder to flag in a standard editorial pass” — SuprMind AI.
- Reviewers trust confident-sounding language; AI is trained to produce it
- Manual spot-checks don’t scale past 10-15 articles per month
- Review bottlenecks create pressure to publish without full verification
Verification infrastructure replaces reliance on individual reviewer judgment with a systematic protocol that holds at production scale.
What Makes AI Citation Fabrication So Difficult to Catch?
Citation fabrication is difficult to catch because hallucinated references are structurally realistic — real author names, plausible journal titles, accurate-looking publication years. Standard editorial review lacks a mechanism to distinguish a real citation from a well-crafted fake without actively verifying each source against the original record.
The Anatomy of a Hallucinated Reference
The research on citation hallucination is specific about what makes fabrications hard to detect. “Hallucinated citations are not random inventions but patterned recombinations of real authors, journals, dates, and keywords, with duplication occurring in nearly 30% of cases” — arXiv:2604.16407.
- Real author names attached to papers they didn’t write
- Legitimate journal titles with fabricated volume and page numbers
- Plausible DOIs that return 404 errors on lookup
- Publication years that match the topic’s research timeline
The plausibility is the problem. An AI-generated citation looks exactly like a real one until you check the source.
Why Deep Research Agents Make the Problem Worse
Counter-intuitively, more sophisticated AI research workflows produce more citation failures, not fewer. Deep research agents hallucinate at higher rates than standard search-augmented models — they generate more references, but additional volume compounds the verification gap.
- Reasoning models exceed 10% hallucination rates on enterprise-length benchmarks
- Chain-of-thought prompting increases hallucination risk by up to 12% in complex domains
- More citations per article means more verification touchpoints required, not fewer
A research agent that generates 15 citations with 3 fabricated ones is a liability, not an asset.
How Fabricated Citations Replicate Across the Web
The long-term damage from citation fabrication extends beyond the original article. “An analysis of over 4,000 research papers accepted and presented at NeurIPS 2025 uncovered more than 100 AI-hallucinated citations across at least 53 papers that had already passed peer review” — arXiv:2602.15871v1.
Hallucinated citations ingested by subsequent AI models create a recursive fabrication loop where the same invented reference appears across dozens of derivative documents.
- Fabricated citations are duplicated in nearly 30% of cases
- AI training data ingests previous AI errors, reinforcing false references
- Errors in early articles influence later production if verification isn’t reset each cycle
The verification problem compounds over time unless a structured protocol interrupts the loop at the source.
What Are the Real Options for How to Verify AI Content Sources at Scale?
Three distinct approaches exist for verifying AI content at scale: manual review, automated tools, and structured research-first workflows. Each has a place in a production system and a ceiling. Understanding how each approach breaks down is more useful than treating the verification of AI content sources as a single-solution problem.
Manual Spot-Check Approaches
Manual verification works at low volume — a content manager reviewing 8-10 articles per month can reasonably spot-check citations and flag suspicious claims. The ceiling is the scale.
- Effective for teams publishing fewer than 15 articles per month
- Requires reviewer familiarity with credible sources in the topic area
- No documentation trail — verification lives in reviewer judgment, not the system
Manual review doesn’t survive a 50-article month without bottlenecking publication cadence or degrading into a surface-level pass that misses fabricated citations entirely.
Automated Verification Tools
Automated citation-checking tools flag non-resolving URLs, detect hallucinated DOIs, and cross-reference claims against structured databases. They reduce manual burden and catch the most obvious fabrication patterns.
- URL validation tools catch a significant share of hallucinated links
- Fact-checking APIs can cross-reference statistical claims against known data sets
- Schema markup tools identify entity density gaps that affect AI search visibility
Automated tools handle detectable failure modes — but not contextual fabrications where a real URL is attached to a statistic the source never published. Human judgment remains necessary for that layer.
Structured Research-First Workflows
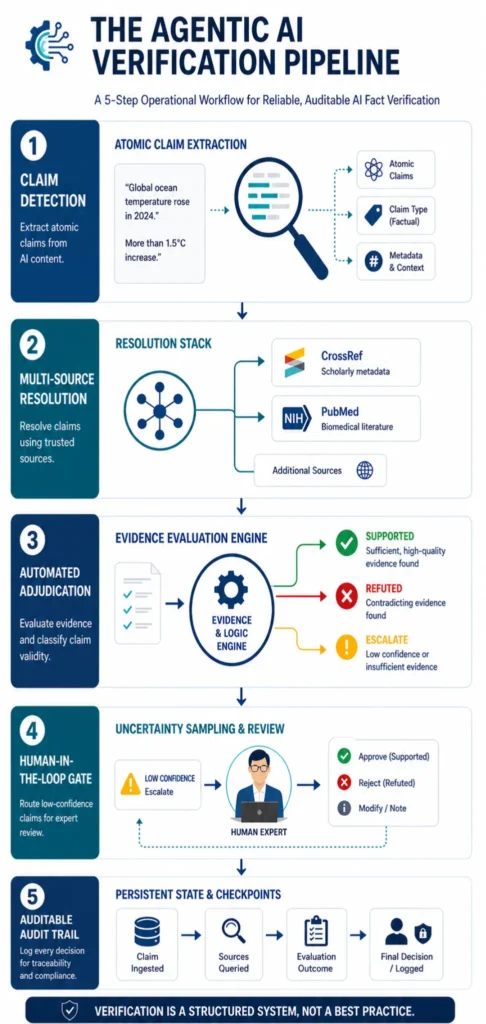
The most defensible approach to verifying AI content sources is architectural: build verification into the production workflow before AI generation begins. Research-first workflows use verified source documents as generation input, extract exact quotes with line numbers, and label each citation as STAT or CLAIM before drafting begins.
- Verification happens at the research stage, not the review stage
- Exact quote extraction eliminates paraphrase drift and interpretation errors
- Line-number documentation creates an audit trail that survives compliance review
The constraint shifts from “can we review enough articles?” to “did we build the research protocol correctly?”
If your operation needs to produce 20-50+ articles per month without creating compliance exposure, Content Ops Lab builds the infrastructure to make that possible. Contact us to discuss your content production requirements.
How Does a Verification Layer Actually Work in a Regulated Content Operation?
A verification layer is a set of mandatory checkpoints that intercept AI output before it is published—not a review process run after the fact.
The Human-in-the-Loop Requirement
The regulatory framework for AI content in regulated industries is becoming explicit. “FDA cautioned the company that AI-generated outputs or recommendations must undergo review and approval by an authorized Quality Unit (QU) representative” — DLA Piper.
- AI generation and compliance sign-off are legally distinct functions
- Human review isn’t a best practice — it’s a regulatory requirement in healthcare and adjacent industries
- The FDA’s cGMP ruling established that AI cannot self-verify compliance with legal standards
For multi-location healthcare operators, this is the current standard — and it applies to content production as much as it applies to manufacturing documentation.
STAT vs. CLAIM Labeling as an Audit Trail
The STAT vs. CLAIM labeling framework distinguishes citations containing numerical data — which require line-number verification against the source — from sourced statements asserting a position without quantitative backing. Treating all citations uniformly wastes review capacity.
- STAT labels: require line-number verification against the original source
- CLAIM labels: require source credibility check and context verification
- Labeling happens at the research extraction stage, before generation begins
Every claim in a published article traces to a specific source, a specific line, and a specific reviewer decision — not a general “we fact-checked this” assertion.
Line-Number Documentation and Source Cross-Checking
Line-number documentation makes verification auditable. When a citation is extracted as an exact quote with a source line number recorded, any reviewer can trace the claim to its origin in under 60 seconds.
- Exact quote extraction prevents paraphrase drift that changes meaning
- Line numbers enable rapid audit of any specific claim under review
- Cross-checking against the source confirms the quote is in context, not misrepresented
Paraphrasing is where fabrication hides. Exact quotes eliminate the gap between what the source said and what the article claims the source said.
How Does Citation-Verified Content Perform in AI Search?
Citation-verified content performs measurably better in AI search because AI systems evaluate structural trust signals — not just keyword relevance. “AI Overviews are built to only surface information that is backed up by top web results, and include links to web content that supports the information presented in the overview” — Google (Official Documentation). Verification infrastructure doesn’t just protect against compliance failure — it directly improves AI citation eligibility.
Why AI Systems Reward Structural Trust Signals
AI retrieval systems look for entity density, corroboration with the Knowledge Graph, and answer-first formatting that cleanly extracts into a summary response. Generic AI content fails these filters because it provides no additional information beyond what the AI has already indexed in its corpus.
- AI systems fragment text into semantic passages and evaluate each independently
- Content buried in a narrative structure fails the extractability filter
- Confident, verified claims with source attribution score higher for corroboration
Content that passes these filters gets cited. Content that doesn’t is invisible, regardless of how many times it’s published.
Entity Density and Information Gain as Ranking Factors
The structural difference between citation-eligible content and generic AI output is measurable. “Heavily cited content has an entity density of 20.6% compared to 5-8% in standard text” — Redot Global. That density gap signals to AI systems that the content is grounded in verifiable reality rather than probabilistic generation.
- Entity density: 20.6% in citation-eligible content vs. 5-8% in generic output
- Google’s February 2026 core update increased information gain weighting as a ranking signal
- Original analysis and proprietary data outperform aggregated rewrites
The gap between generic AI content and citation-eligible content isn’t about the quality of writing — it’s about structural grounding.
What Verified Content Delivers in Production
The production case for verification-first methodology comes from live deployment data. A 12-location regulated healthcare organization running verification-first content production for 23 months achieved 45% of all leads from organic search — outperforming paid search nearly 2:1. AI search traffic converted at 21.4% average over 8 months, compared to a 3.32% site baseline.
- 45% organic lead share across a 12-location footprint
- AI search CVR: 21.4% vs. 3.32% site average — 6.4x performance multiplier
- 887% ChatGPT traffic growth in 7 months
Verified content produces the structural signals AI systems require for citation selection. The conversion data is the downstream result.
Is Building a Verification Infrastructure Worth the Investment?
Building verification infrastructure is worth the investment if you are publishing at scale in a regulated or semi-regulated industry. The question isn’t whether you can afford to verify — it’s whether you can absorb the alternative.
The Cost of Getting It Wrong in Regulated Industries
The regulatory environment for AI content is tightening, not stabilizing. The FDA’s April 2026 cGMP Warning Letter, FTC’s Operation AI Comply, and California’s SB 53 collectively establish that organizations are accountable for unverified AI outputs — and the penalty structures are explicit.
- FDA Warning Letter: AI-generated outputs require authorized Quality Unit review
- FTC enforcement: AI-generated false testimonials constitute deceptive conduct
- State-level AI regulations: penalties reaching $1 million per violation in some jurisdictions
The compliance exposure isn’t theoretical for operators in healthcare, legal, or financial services.
What Verification-First Production Actually Requires
Verification infrastructure is a workflow architecture decision, not a technology purchase. The core components — research-first protocol, exact-quote extraction, STAT/CLAIM labeling, and human review checkpoint — can be built by an existing content team with the right system documentation.
- Research-first protocol: verified source documents precede AI generation
- Exact-quote extraction: no paraphrasing between source and publication
- STAT/CLAIM labeling: differentiated verification standards by evidence type
- Human review checkpoint: mandatory before any content is published
The constraint is operational discipline at production volume, which is where most internal teams hit their ceiling.
Done-For-You vs. System Build for Verification Infrastructure
Two implementation paths exist with Content Ops Lab. Done-For-You delivers verified content as a managed service — publish-ready articles that have already cleared the verification protocol. System Build delivers the infrastructure itself: templates, workflows, training, and documentation for your team to operate independently.
- Done-For-You: fastest path to verified content at scale; no internal build required
- System Build: full ownership of the system; appropriate for teams with internal production capacity
- Both models deliver the same verification standard; the difference is who operates the workflow
The right model depends on whether your team has the capacity to run a systematic production workflow or needs the output without the operational overhead.
How Content Ops Lab Builds Content Infrastructure
A 12-location regulated healthcare organization published 1,000+ citation-verified articles and pages over 23 months — zero compliance violations, 45% of all leads from organic search, AI search traffic converting at 21.4% average. That production environment is the proof-of-concept Content Ops Lab brings to every client engagement.
- 23-month production test inside a 12-location regulated healthcare organization
- 1,000+ citation-verified articles and pages delivered with zero compliance violations
- 45% of all leads from organic search — outperforming paid search nearly 2:1
- AI search converting at 21.4% vs. 3.32% site baseline — 6.4x performance multiplier
- 887% ChatGPT traffic growth in 7 months across the production period
- 653% impression growth and 1,700% click growth for an emerging brand in 14 months
- 5x production scale: 10 articles/month to 50+ without adding headcount
- Dual-brand methodology validated on both mature brand maintenance and emerging brand growth
The Content Ops Lab Production System
Every engagement runs on the same four-stage infrastructure — research, verification, optimization, and delivery executed as a unified system, not independent steps.
- Research: Verified source documents and exact-quote extraction before generation begins
- Verification: Line-by-line citation cross-check, STAT vs. CLAIM labeling, full audit trail
- Optimization: Simultaneous targeting across Google, ChatGPT, Perplexity, Claude, and Gemini
- Delivery: WordPress staging or Google Docs — reviewed, compliant, and publish-ready
The system is transferable. In a System Build engagement, your team operates it. In Done-For-You, we run it on your behalf.
Ready to build a content infrastructure that scales without the compliance risk? Get in touch today — we’ll assess your current content operation and outline what a systematic approach would look like for your organization.
FAQs About How to Verify AI Content Sources
Can’t we just manually fact-check AI-generated content after it’s written?
Manual fact-checking works at low volume — 8 to 12 articles per month — but doesn’t scale without creating publication bottlenecks or degrading into surface-level review. The more fundamental problem is that post-generation review is structurally reactive. Verification-first workflows prevent fabrications from entering the draft at all by grounding generation in pre-verified source documents.
How long does it take to build a citation verification workflow for a content team?
A functional verification workflow takes 4 to 8 weeks to design and document. Full production integration, including team training and live article output, typically requires 10 to 12 weeks. A System Build engagement includes all five implementation phases, along with 90 days of post-launch support, to ensure the workflow holds up at production volume.
What happens if unverified AI content violates FDA or FTC standards?
The FDA’s April 2026 Warning Letter established that organizations are directly accountable for AI outputs — compliance cannot be delegated to the AI tool. FTC enforcement under Operation AI Comply targets fabricated claims in consumer-facing content. State-level regulations carry penalties of up to $1 million per violation. The direction is consistent: AI output requires human verification before publication.
How is knowing how to verify AI content sources different from what a traditional agency delivers?
Traditional agencies deliver content drafted with AI tools and reviewed for readability — not source-verified against original research documents. A verification-first system starts with source research, extracts exact quotes with line numbers, labels each citation with its evidence type, and requires human sign-off before publication. The output looks similar; the compliance defensibility is categorically different.
Is Done-For-You or System Build better for operators who need to know how to verify AI content sources at scale?
Done-For-You is the right model if your team lacks the capacity to operate a systematic production workflow — you receive verified, publish-ready content without the operational overhead. System Build is appropriate if you have internal production capacity and want long-term full ownership. Both models deliver the same verification standard; the decision is whether you want to own the system or the output.
Key Takeaways
- Unverified AI content creates compliance exposure that scales with publishing volume — one hallucinated statistic can propagate across every location page simultaneously
- Hallucinated citations are structurally realistic — real author names, plausible journals, fabricated references — making post-generation review an unreliable detection method
- Verification-first workflows prevent fabrications at the source by grounding AI generation in pre-verified research documents with exact-quote extraction and line-number documentation
- A 12-location regulated healthcare organization published 1,000+ citation-verified articles with zero compliance violations over 23 months — verification infrastructure at scale is operationally achievable
- AI search platforms reward the same structural signals that verification produces: entity density, corroborated claims, answer-first formatting — verified content performs better, not just safer
- The regulatory environment is tightening: FDA, FTC, and state-level AI laws are actively establishing that organizations are accountable for unverified AI outputs
- Two implementation paths exist — Done-For-You managed production, and System Build infrastructure handoff — the verification standard is identical in both
Build Content Infrastructure That Compounds: How to Verify AI Content Sources
AI content without verification is a probabilistic guess published at scale. A 2026 benchmark across 37 models reported hallucination rates between 15% and 52% — meaning that for every six articles your team publishes from unverified AI output, at least one contains a fabricated claim.
For multi-location operators in regulated industries, that error rate isn’t a quality problem. It’s a liability timeline. Operators who build verification infrastructure now capture the AI search performance advantage and eliminate compliance exposure before the regulatory environment forces the issue.
Content Ops Lab has run this system for 23 months in a regulated industry — the methodology is proven, the results are documented, and the infrastructure is transferable to your operation.
Related: Done-for-You vs In-House Content Systems – Which Scales for Multi-Location Brands?