
What Are Multi-Location Content Systems?
Multi-location content systems are centralized production infrastructures that govern how content is researched, verified, created, and distributed across every location in an enterprise — replacing ad hoc execution with a single, auditable workflow.
Without multi-location content systems, scaling content across 5, 12, or 50 locations doesn’t produce proportionally more output. It produces proportionally more operational debt. “Employees spend nearly 20% of their work week searching for internal information or tracking down colleagues who can help with specific tasks. That translates to roughly one full day per week lost to hunting through disconnected systems rather than creating value” — Aprimo.
For multi-location operators managing content at scale, that isn’t a productivity problem. It’s a structural one. Content Ops Lab built its methodology inside a 12-location regulated healthcare organization — 1,000+ citation-verified articles delivered with zero compliance violations over 23 months.
Related: What Is Content Infrastructure for Multi-Location Brands?
Why Do Multi-Location Content Operations Break Before They Hit Their Growth Targets?
Multi-location content systems fail not from lack of output but from lack of infrastructure. As the location count grows, coordination complexity grows exponentially — and without a centralized system to absorb it, the production process consumes itself.
The Throughput Ceiling Mechanism
Every content operation has a finite capacity for concurrent work before quality begins to degrade. In multi-location environments, this ceiling arrives earlier than expected because the system is burdened by manual orchestration at every handoff.
- Throughput ceiling is structural, not a headcount problem
- Adding locations multiplies coordination paths, not just workload
- Manual handoffs are where context — and compliance — get lost
- Quality degrades before volume does
The ceiling doesn’t announce itself. It shows up as slow approvals, inconsistent brand voice, and compliance flags that weren’t there six months ago.
Coordination Costs That Kill Productivity
“60% of the average knowledge worker’s time is consumed by coordination activities rather than the skilled, strategic work they were hired to perform” — SpeakWise.
In a multi-location marketing department, the majority of your team’s capacity is consumed by managing work rather than doing it.
- Status updates, approvals, and version reconciliation
- Rebuilding context at every stage of the workflow
- Location-level stakeholders pulling in different directions
- No shared system means no shared standard
Coordination overhead isn’t visible on a content calendar. It shows up in missed deadlines, duplicate work, and content that doesn’t reflect the brand.
Tool Sprawl and the Fragmentation Tax
“The average company used 112 SaaS applications in 2024, with employees interacting with 10 to 14 different tools every day” — SpeakWise.
Each disconnected tool adds a communication edge to an already-strained network — and in decentralized, multi-location operations, that edge is where brand standards break down.
- Location A uses one project tool, Location B uses another
- No single source of truth for brand assets or approved content
- Outdated or off-brand content gets published without a check
- Tool proliferation shifts effort from creating value to managing tools
The fragmentation tax cannot be solved by adding more tools. It is solved by centralizing the workflow.
What Options Do Multi-Location Operators Actually Have for Scaling Content Production?
Operators scaling content across multiple locations have three primary options: build internal capacity, hire a traditional agency, or deploy generic AI tools. Each can produce content. None of them — without centralized governance — can produce content that stays consistent, compliant, and competitive in AI search at scale.
Internal Teams at Scale
Internal teams have a hard ceiling of around 4-8 articles per month before bandwidth runs out. Pushing past that ceiling by adding writers or coordinators typically increases coordination complexity faster than output.
- Tribal knowledge doesn’t transfer without documentation systems
- Brand voice depends on who’s writing, not what the system requires
- No systematic citation verification — accuracy is person-dependent
- New hires consume existing bandwidth before adding capacity
Adding headcount to a fragmented workflow produces more edges, not more throughput. The underlying system has to change first.
Traditional Agencies and Their Ceiling
Traditional agencies can produce volume. The question is whether that volume holds up in regulated industries or AI search environments — and the answer is usually no.
- Generic research from surface-level sources, not verified citations
- One-draft delivery with no systematic quality control
- AI content without verification infrastructure — fabrications enter published work
- Linear cost model: more volume requires more writers, not better systems
Traditional agencies are built for the 2019-era SEO. Multi-location operators who need AI citation performance and compliance assurance need something categorically different.
Generic AI Tools Without Governance
Generic AI tools accelerate production. They do not solve the verification problem — they scale it. “19.9% of AI-generated references were completely fabricated, with no traceable existence in the scholarly record. Among the remaining citations, 45.4% contained serious bibliographic errors” — Enago.
- AI writes from memory, not from verified source documents
- No compliance layer — every article is a liability in regulated industries
- Output is generic unless structured knowledge is integrated into the workflow
- Speed gain is real; so is the liability exposure
The gap between AI production speed and AI production safety is the verification infrastructure.
What Does a Centralized Multi-Location Content System Actually Require?
A centralized multi-location content system requires three interdependent components: verification infrastructure built before generation, entity consistency managed from a single governance layer, and workflow orchestration that replaces manual handoffs with auditable process. Without all three, centralization is structural in name only.
Verification Infrastructure Before Generation
The standard model — generate content, then verify it — doesn’t scale. In multi-location environments, verification after generation creates a bottleneck that grows with volume. The only durable solution is to invert the sequence: verify sources before generation begins.
- Research documents are assembled and cited before any AI writes a word
- Claims traced to specific sources with line-number documentation
- STAT vs. CLAIM labeling applied at the research stage, not the edit stage
- Compliance risk is addressed upstream, not caught downstream
This is what makes AI content defensible in healthcare, legal, and financial environments. Not the tools — the sequence.
Entity Consistency Across All Locations
AI retrieval systems build knowledge graphs — structured maps of entities, relationships, and authoritative data. If NAP data, service descriptions, and brand voice vary across locations, the knowledge graph fragments. Fragmented entities don’t get cited.
- Consistent Name, Address, Phone data across every location page
- Unified service and provider descriptions, not location-by-location variations
- Centralized schema markup deployed without template-level breakage
- Brand vocabulary aligned so AI vector embeddings recognize a coherent entity
Entity consistency is the technical prerequisite for AI search visibility, not an SEO checkbox.
Governance Architecture Over Ad Hoc Execution
Governance defines who has authority over what, how decisions are made across jurisdictions, and how local variation is handled without breaking the centralized standard. Without it, every location becomes a decision node — and decision nodes multiply coordination failures.
- Role-based permissions separate local editing from core brand control
- Centralized intake channels prevent redundant or off-brand production
- State-level compliance handled as structured exceptions, not separate workflows
- Modular content reuse across regions cuts production overhead without sacrificing differentiation
The shift from management to governance enables a 12-location operation to run on the same production standard as a 3-location one.
If your operation needs to produce 20-50+ articles per month without sacrificing compliance or quality, Content Ops Lab builds the infrastructure to make that possible. Contact us to discuss your content production requirements.
How Does AI Search Change the Infrastructure Requirements for Multi-Location Brands?
AI search doesn’t change what good content looks like — it changes what determines whether that content gets surfaced at all. For multi-location content systems, the new selection criteria are structural: E-E-A-T signals, knowledge graph density, and structured formatting.
“96% of AI citations go to sources with strong E-E-A-T signals… pages ranking #6–#10 with strong E-E-A-T are cited 2.3x more frequently than #1-ranked pages with weak E-E-A-T”— Ziptie.dev / Wellows Analysis.
E-E-A-T as a Technical Requirement
E-E-A-T signals are measured at the infrastructure level, not the article level. A brand that publishes verified, consistently structured content from credible sources systematically signals E-E-A-T.
- Verified citations signal authoritativeness to AI retrieval systems
- Consistent brand voice and vocabulary create vector embedding alignment
- Answer-first structure makes content extraction-ready for AI Overviews
- Question-based H2 architecture mirrors how users query conversational AI
E-E-A-T is an infrastructure output. It compounds across a production system — it cannot be manufactured one article at a time.
Knowledge Graph Fragmentation and Invisible Brands
“Knowledge graphs are the backbone of modern AI retrieval. If your structured data is inconsistent, the graph fragments — and fragmented entities don’t get cited” — Dr. Amit Singhal, former SVP of Search, Google via XSeek.
For multi-location brands, this is the operational risk most marketing leaders haven’t fully mapped.
- Inconsistent location metadata creates entity ambiguity in knowledge graphs
- Varying service descriptions prevent AI from resolving a canonical definition
- Each location page that deviates from the standard degrades the whole network’s credibility
- Fragmented entity data produces functional brand invisibility in AI-generated answers
The multi-location brand that loses the knowledge graph consistency battle doesn’t rank lower. It disappears from AI-generated answers entirely.
Structured Data as a Centralized Asset
“Pages using Article and FAQPage schema appear in 2.3x more AI Overview citations than those without” — Global Reach. That advantage holds only if the schema is deployed consistently, which requires centralized implementation rather than location-by-location manual updates.
- JSON-LD deployed from a central system reduces template breakage by 60%
- FAQPage schema targets the question-and-answer format AI systems extract directly
- Centralized schema governance prevents local variations that corrupt structured data signals
- Schema markup converts content quality into AI citation eligibility
Structured data is a content operations decision. It has to be made centrally.
Related: Done-for-You vs In-House Content Systems – Which Scales for Multi-Location Brands?
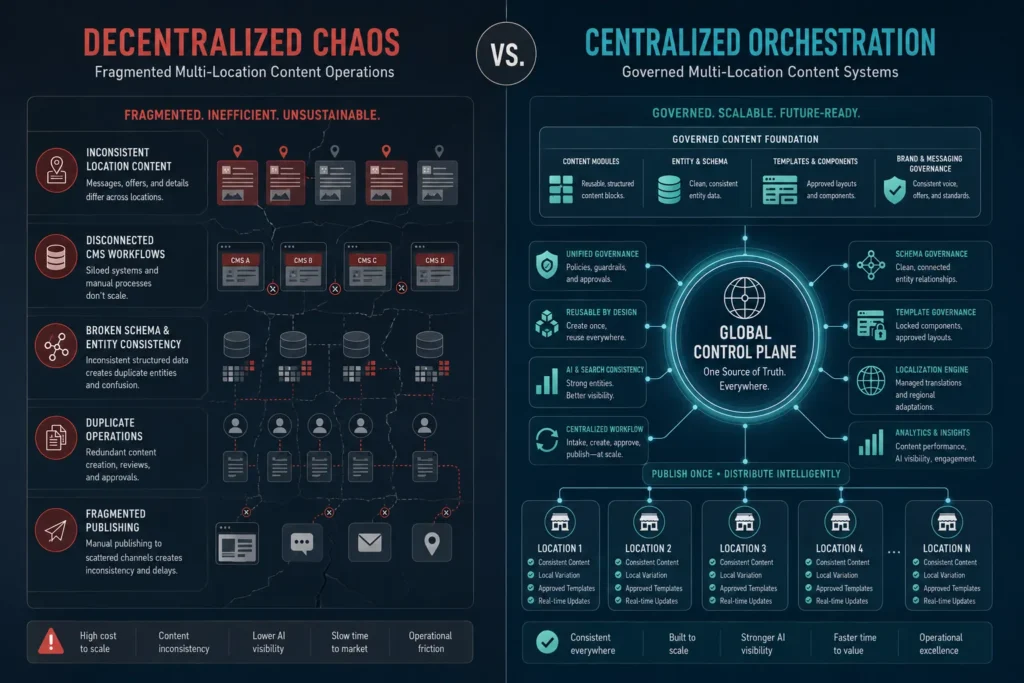
What Does Verification-First Content Infrastructure Actually Deliver in Production?
Verification-first infrastructure delivers three outcomes ad hoc AI content cannot: clean citation records, defensible compliance documentation, and compounding search authority. The production data from a 23-month healthcare deployment makes the performance case concrete.
Citation Integrity at Scale
“Every IT function has a throughput ceiling. When that ceiling is reached, adding more AI mandates does not produce more output — it degrades everything already in motion” — Graph Digital.
A multi-location brand publishing 50 articles per month without verification infrastructure isn’t producing content — it’s producing liability at scale.
- Verification-first workflow catches fabrications before they enter published work
- Line-number documentation creates an auditable citation record for every claim
- STAT vs. CLAIM labeling applies appropriate scrutiny to different evidence types
- Zero-hallucination output is achievable only with structured pre-generation research
Citation integrity isn’t a quality-of-life improvement. In healthcare and legal environments, the distinction is between a content program and a compliance exposure.
Compliance Assurance in Regulated Industries
Regulated industries require content that can withstand scrutiny. Every medical claim traced to a credible source, every legal assertion appropriately qualified, no fabricated statistics in published material. These requirements don’t ease at higher volume. They compound.
- Centralized verification protocols apply the same standard to every article
- Compliance is built into the production sequence, not reviewed at the end
- State-specific compliance requirements are handled as governed exceptions
- 1,000+ articles delivered across a 12-location regulated healthcare organization with zero compliance violations
Zero violations over 23 months of production at scale is not an accident. It is the result of a system built with compliance as an architectural requirement.
The Compounding Advantage of Auditable Content
Search authority compounds. Each verified, citation-rich article strengthens the knowledge graph signals that determine AI citation eligibility. Brands that invest in verification infrastructure early create an accumulating advantage that unverified competitors cannot close by publishing more volume.
- 188 question-based keywords ranking, 83% in positions 1-10
- AI search traffic converting at 21.4% average — 6.4x the site baseline
- 887% ChatGPT session growth in 7 months from a verified, structured content foundation
- Organic search delivering 45% of all leads — outperforming paid search nearly 2:1
Content published without a verification foundation doesn’t compound. It accumulates debt.
Done-For-You vs. System Build: Which Multi-Location Content Model Fits Your Operation?
The choice between Done-For-You and System Build is an operational question, not a quality question. Both models deliver the same production standards and verification infrastructure. The decision turns on whether your organization wants to own the system or have it operated for you.
Choosing the Right Engagement Model
Done-For-You is for operators who need production capacity immediately without building internal systems. System Build is for operators who want full ownership of the infrastructure and have the internal team to operate it after handoff.
- Done-For-You: Content Ops Lab runs research, generation, verification, and delivery
- System Build: Content Ops Lab builds the system, trains the team, and exits after 90-day support
- Both models produce the same citation-verified, multi-platform-optimized output
- The right model depends on internal bandwidth and ownership preference
Neither model requires the operator to become an AI content expert. Both require commitment to systematic production standards.
What Implementation Actually Involves
System Build follows a 12-week implementation: discovery and gap analysis, knowledge documentation, template development, team training, and 90-day post-launch support. Done-For-You begins with onboarding and moves into weekly content delivery with a 48-72 hour revision turnaround.
- The discovery phase identifies operational debt, keyword strategy, and workflow gaps
- Knowledge documentation converts SME expertise into reusable content assets
- Template development encodes production standards into repeatable workflows
- Training ensures the internal team can operate the system without ongoing dependency
Implementation is a defined process. The timeline is 12 weeks to operational capability.
How to Evaluate Whether Your Operation Is Ready
The readiness question isn’t about company size — it’s about content volume requirements and operational pain. If your organization needs 20-50+ articles per month and operates in a regulated industry, the case for infrastructure is already made.
- 5+ locations with active content needs is the operational threshold
- Regulated industry exposure makes verification infrastructure mandatory, not optional
- Current content budget of $5,000-$15,000/month is the investment range where systematic infrastructure outperforms agency spend
- Existing compliance concerns or citation audit risk accelerate the build decision
The operator who builds infrastructure in 2026 captures citations that compound for years. The operator who waits builds into a more competitive environment with less first-mover runway.
How Content Ops Lab Builds Multi-Location Content Infrastructure
A multi-location healthcare organization ran 1,000+ citation-verified articles through a single unified production system over 23 months — with zero compliance violations and consistent output at 50+ articles per month. Content Ops Lab productizes that system for multi-location operators who need the same infrastructure without having to build it from scratch.
- 23-month production test inside a 12-location regulated healthcare organization
- 1,000+ citation-verified articles and pages delivered with zero compliance violations
- 45% of all leads from organic search — outperforming paid search nearly 2:1
- AI search converting at 21.4% average vs. 3.32% site baseline — 6.4x performance multiplier
- 653% impression growth and 1,700% click growth for an emerging brand built from near-zero organic presence
- 5x production scale: 10 articles/month to 50+ without adding headcount
- 887% ChatGPT traffic growth in 7 months (July 2025 – February 2026)
- Dual-brand methodology validated on both mature brand maintenance and aggressive emerging brand growth
The Content Ops Lab Production System
Every engagement — Done-For-You or System Build — runs on the same four-stage infrastructure built on 23 months of live production testing in a regulated industry.
- Research: Verified sources assembled before generation — no AI writing from memory
- Verification: Line-by-line citation cross-check, STAT vs. CLAIM labeling, full audit trail
- Optimization: Multi-platform build for Google + ChatGPT + Perplexity + Claude + Gemini simultaneously
- Delivery: WordPress staging or Google Docs — publish-ready, reviewed, and compliant at handoff
The infrastructure is transferable, version-controlled, and designed to improve through production — not in spite of it.
Ready to build a content infrastructure that scales without the compliance risk? Get in touch today — we’ll assess your current content operation and outline what a systematic approach would look like for your organization.
FAQs About Multi-Location Content Systems
Can’t we assign one person at each location to manage local content instead of building multi-location content systems?
Decentralized ownership creates the exact fragmentation that degrades brand consistency and compliance. When each location controls its own content, there is no mechanism to enforce citation standards, maintain entity consistency, or prevent off-brand publication. A centralized system with role-based permissions allows local managers to update safe fields — such as hours and staff photos — while protecting core brand and compliance standards from location-level variation.
How long does it take to build a centralized multi-location content system, and when do results appear?
System Build implementation runs 12 weeks across five phases: discovery, knowledge documentation, template development, team training, and 90-day post-launch support. Done-For-You engagements begin content delivery during onboarding. Search results typically emerge in the 3-6 month range as indexed content accumulates authority. AI search citation performance follows — the 887% ChatGPT traffic growth documented in Content Ops Lab’s case study developed over 7 months of consistent, verified content publication.
How does a centralized content system reduce compliance risk for healthcare or legal organizations?
Centralized systems address compliance at the production stage, not the review stage. Verification-first workflows require every claim to trace back to a specific source document before generation begins — eliminating the risk of hallucination that produces fabricated statistics. Line-number documentation creates an auditable record for every published claim, and role-based governance prevents non-compliant content from reaching publication without central review—the result: 1,000+ articles delivered in a regulated healthcare environment with zero compliance violations over 23 months.
How is a content operations system different from what a traditional content agency delivers?
Traditional agencies deliver articles. Multi-location content systems deliver infrastructure — research protocols, citation verification workflows, multi-platform optimization standards, and governance architecture that scales without adding headcount. The difference shows up in regulated industries and AI search environments, where generic agency output fails both verification audits and AI citation eligibility requirements.
What does a Done-For-You content system engagement actually include for a multi-location business?
Done-For-You engagements include end-to-end production: verified research, AI-assisted generation, line-by-line citation cross-checking, multi-platform optimization, Grammarly review (≥95 score standard), and delivery via WordPress staging or Google Docs. Monthly deliverables include 20-50+ articles, keyword research, content calendar management, and performance tracking. The operator provides strategic direction and reviews final deliverables. Content Ops Lab handles every production step.
Key Takeaways
- Multi-location content systems are centralized production infrastructures — not content calendars or agency retainers — that govern research, verification, generation, and distribution from a single workflow
- Fragmentation is the root failure: coordination overhead, tool sprawl, and decentralized execution create throughput ceilings that adding headcount cannot solve
- Verification infrastructure must precede generation in regulated industries — 1 in 5 AI-generated references are completely fabricated, and that failure rate scales with volume if the system doesn’t address it upstream
- AI search visibility is an infrastructure output: E-E-A-T signals, knowledge graph consistency, and structured data deployment are determined at the system level, not the article level
- Content Ops Lab’s 23-month production test across a 12-location healthcare organization produced 1,000+ citation-verified articles, zero compliance violations, and AI search conversion rates of 21.4% — 6.4x the site baseline
- Organic search generated 45% of all leads over 6 months, outperforming paid search nearly 2:1 — a direct result of systematic, verification-first content infrastructure
- The first-mover window for AI search citation dominance is measured in quarters: operators who build infrastructure now compound authority that late entrants cannot replicate by volume alone
Build Content Infrastructure That Compounds: Multi-Location Content Systems
Multi-location content systems are not a content strategy upgrade. They are an operational prerequisite for competing in an environment where AI systems select citations based on entity consistency, verification integrity, and structural formatting — not keyword density or publication volume.
The operators who build centralized production infrastructure in 2026 will hold citation advantages that compound for years. Those who continue with decentralized, unverified workflows will face rising remediation costs as AI search becomes the primary channel for high-intent research traffic.
Content Ops Lab’s methodology was built within a live, regulated-industry operation—not theorized in a conference room. The infrastructure is documented, transferable, and proven at scale.