How Does E-E-A-T Apply to AI Search?
E-E-A-T in AI search is not a secret ranking formula—but it now determines whether AI systems can retrieve, trust, and cite your content at all. Google’s own documentation confirms that “E-E-A-T itself isn’t a specific ranking factor, using a mix of factors that can identify content with good E-E-A-T is useful” — Google Search Central. AI search systems go further: they retrieve and synthesize information from a selective pool of sources, and brands that lack clear authorship, verified evidence, or consistent entity signals often do not enter that pool. The penalty is not a ranking drop—it is exclusion.
Content Ops Lab has spent 23 months building content infrastructure that makes trust machine-readable at scale—across 1,000+ citation-verified articles in a regulated, multi-location healthcare environment. The finding is clear: in AI search, credibility is engineered into the production system, not added during editing.
Related: What Makes a Source Citation-Worthy to AI Search Engines?
Why Does E-E-A-T Matter More in AI Search?
E-E-A-T in AI search matters more now, not because it became a ranking algorithm, but because AI search changed the visibility environment around trustworthy content. The bar for source selection got higher—and most content operations were not built for it.
E-E-A-T Is a Trust Framework, Not a Ranking Switch
Google’s quality rater guidelines “don’t directly influence ranking” — Google Search Central Blog. E-E-A-T describes what trustworthy content looks like; it does not function as a direct scoring mechanism.
- E-E-A-T: Experience, Expertise, Authoritativeness, Trustworthiness
- Not a direct ranking factor in Google or any documented AI platform
- Functions as a quality description, not a scoring formula
- Signals work together; no single element guarantees visibility
The more important question is not “does E-E-A-T rank us?” but “does our content infrastructure produce the trust qualities AI systems need?”
Trust Is the Element That Carries the Most Weight
Google’s documentation makes one thing clear: “trust is most important. The others contribute to trust, but content doesn’t necessarily have to demonstrate all of them” — Google Search Central. Trustworthy content is verifiable, accurate, honest about its sources, and produced by people with legitimate credentials.
- Trust enables AI systems to ground answers in reliable evidence
- Experience, expertise, and authority all feed into demonstrable trust
- Verified sourcing is a core trust signal, not a bonus
- Consistency across pages and entities reinforces or undermines trust
When trust breaks down at the source level, generative systems either misrepresent information or avoid the source entirely—neither outcome supports AI visibility.
The Visibility Environment Around Trust Has Changed
Generative AI answers typically cite a handful of sources—not the ten to twenty results traditional search displays simultaneously. “RAG enhances the accuracy and credibility of the generation, particularly for knowledge-intensive tasks, and allows for continuous knowledge updates” — arXiv.
- Generative AI selects fewer visible sources per answer than ranked search
- Retrieval systems evaluate sources before synthesis, not after
- Weak trust infrastructure produces exclusion, not just a lower position
- AI search is a trust-screening environment, not a ranking competition
How Is AI Search Different From Traditional Search Ranking?
AI search does not rank pages and display them in order. It retrieves sources, evaluates their reliability, synthesizes an answer, and cites the content it used. That sequence changes the competitive game entirely.
Retrieval, Grounding, and Citation Are Not Ranking
In AI search, retrieval selects candidate sources, grounding validates them against the query, synthesis constructs the answer, and citation identifies what was used. Reliability-aware retrieval systems “estimate the reliability of sources and prioritize highly reliable and relevant documents” — EMNLP 2025.
- Traditional search: crawl → rank → display
- AI search: retrieve → ground → synthesize → cite
- Ranking position is one input, not a reliable proxy for retrieval eligibility
- Source reliability is evaluated before a brand appears in any answer
Brands that approach AI visibility through ranking logic alone are solving the wrong problem.
Trust Dimensions Extend Beyond Factual Accuracy
Industry research frames AI trustworthiness broadly—”across six dimensions: factuality, robustness, fairness, transparency, accountability, privacy” — arXiv. Content that passes a fact-check but lacks editorial transparency can still fail the broader trust screen.
- Factual accuracy is necessary but not sufficient for AI trust
- Transparency about authorship, sourcing, and methodology matters
- Accountability signals (named authors, verifiable credentials) strengthen trust
- Thin or opaque content fails on multiple trust dimensions simultaneously
Building content that clears all these dimensions requires a production system, not a final editing pass.
Position Alone Does Not Determine Citation Eligibility
Third-party analysis from ZipTie Dev suggests that pages with superior E-E-A-T qualities “outperform top-ranked pages by 2.3x in AI citation frequency” — ZipTie Dev. Domain authority also shows a lower correlation with AI citation than traditional SEO models predict, according to Satellite AI analysis — Satellite AI.
- Organic ranking position is not a reliable proxy for AI citation eligibility
- Trust signal quality can offset lower domain authority in some retrieval scenarios
- Complete, well-sourced content may outperform thinner top-ranked pages
- The citation competition is different from the ranking competition
What E-E-A-T Signals Are AI Systems Most Likely to Reward?
No AI platform publicly documents a named E-E-A-T citation framework. The safer and more accurate framing is that E-E-A-T in AI search describes the trust qualities retrieval systems need when selecting sources for grounded answers—not a scoring mechanism, but a useful map of what makes content machine-trustworthy.
Clear Authorship, Credentials, and Review Accountability
Google’s “Who, How, Why” framework asks whether content demonstrates who produced it, how it was produced, and for what purpose — Google Search Central. Machine-readable trust requires named authors with verifiable credentials, clear attribution of reviewers for regulated topics, and editorial standards visible in the content itself.
- Named authors with documented credentials and subject matter experience
- Reviewer attribution for medical, financial, legal, and regulated claims
- Editorial transparency about production standards and source quality
- Author entity consistency across site pages, schema, and off-site profiles
A bio that exists only on an About page does not produce the entity signal that retrieval systems can consistently identify and weight.
Semantic Completeness and Direct Answer Structure
Satellite AI analysis identified a strong correlation between semantic completeness and AI citation patterns — Satellite AI. Third-party data from ZipTie Dev indicates that a significant share of AI citations are drawn from the first third of a page — ZipTie Dev.
- Answer-first structure puts key information where retrieval systems are more likely to find it
- Complete topical coverage reduces query gaps that send AI systems to other sources
- Structured headings, bullets, and data tables improve machine parseability
- Fragmented or thin content loses the completeness signal regardless of topic relevance
Content that requires interpretation to extract the answer is less useful to a synthesis system than content that surfaces it immediately.
Verified Citations and Evidence-First Sourcing
“Google’s automated ranking systems are designed to prioritize helpful, reliable information that’s created to benefit people” — Google Search Central. In operational terms, that means every claim traces to a verifiable source—not vendor assertions, not hedged generalizations, not statistics that cannot be checked.
- Every substantive claim should trace to a named, verifiable source
- Primary research and official documentation outperform secondary or aggregated sources
- In-text citation placement—not grouped footnotes—signals sourcing transparency to machines and humans
- Unverified or vendor-only statistics weaken the trust profile of otherwise strong content
Sourcing standards are not a copyediting concern—they are a structural requirement for AI-retrievable content.
If your operation needs to produce 20–50+ articles per month without sacrificing compliance or quality, Content Ops Lab builds the infrastructure to make that possible. Contact us to discuss your content production requirements.
Why Do Multi-Location Brands Have a Harder E-E-A-T Problem?
Multi-location brands do not face one E-E-A-T problem. They face it dozens or hundreds of times simultaneously—across locations, practitioners, services, and local pages—with each instance capable of undermining the broader site’s trust profile.
Trust Signals Must Scale Consistently Across Every Location
A 12-location brand must consistently demonstrate trust across 12 sets of practitioners, local claims, service pages, and the full entity network that connects them. Google’s automated helpful content system evaluates sites broadly—”this new site-wide signal…classifier process is entirely automated, using a machine-learning model” — Google Search Central Blog.
- Sitewide automated quality signals mean location page quality affects the whole domain
- Practitioner credentials, service descriptions, and local claims must all be accurate and consistent
- Location-level entity data (address, hours, schema) must match across the site and directory listings
- Thin city-swap pages or templated location content dilutes the trust profile of stronger pages
City-swap pages and templated location content are among the highest-risk shortcuts for multi-location AI visibility.
Practitioner and Service Entity Consistency Is a Governance Challenge
For multi-location brands in regulated industries, trust operates at the practitioner level. When practitioner information varies across pages—or is absent from some locations—the content system produces inconsistent entity signals that AI retrieval systems cannot reliably use.
- Practitioner schemas must reflect current credentials, titles, and specializations
- Service descriptions must be consistent in scope and accuracy across all locations
- Entity linking between practitioners, locations, and services must be systematic, not ad hoc
- Review and update cycles must match the pace of practitioner and service changes
Managing entity consistency across a growing network of locations is not a writing task. It requires a governance layer built into the content production workflow.
Content Governance Prevents Compliance and Trust Failures Simultaneously
Content Ops Lab built a production system for a 12-location regulated healthcare client, scaling from 10 articles per month to 50+ while maintaining citation verification and compliance standards. Over 23 months, he scaled production from 10 articles/month to 50+, delivering 1,000+ citation-verified articles and pages while managing dual-brand operations.
- Citation verification must happen at the drafting stage, not the publishing stage
- Compliance review for regulated claims requires SME input embedded in the production system
- Content governance standards must be consistent regardless of which writer or location is involved
- Scale without governance produces compounding trust and compliance risk
The brands most at risk in AI search have high-volume, low-governance operations producing inconsistent signals at scale.
Related: How Do You Get Cited by ChatGPT?
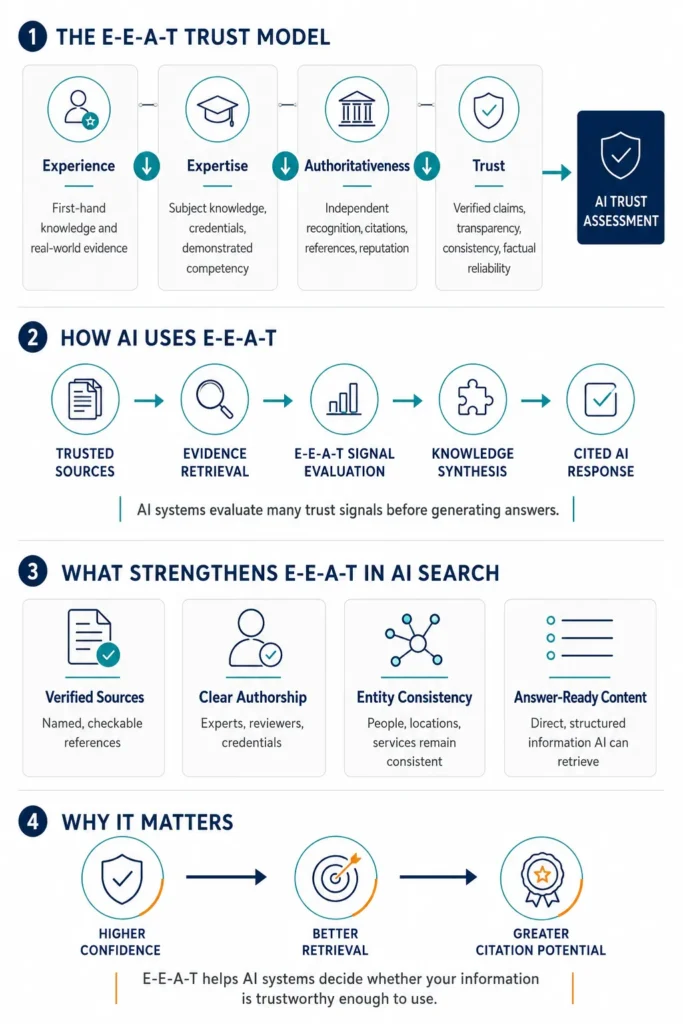
How Should Brands Build E-E-A-T Into Content Infrastructure?
Building E-E-A-T in AI search into content infrastructure means moving verification, accuracy, and attribution decisions into the production design stage—not the final editing pass. If trust depends on catching problems before publishing, the system is already fragile.
Research Standards and Source Control Before Drafting Begins
Source selection, claim verification, and evidence standards must be defined at the workflow level before drafting begins. “Every statistic, claim, and data point verified against source research before publication.” — Content Ops Lab Production Standard
- Define an approved source hierarchy: primary research, official documentation, peer-reviewed studies
- Require citation trail documentation before drafting begins, not after
- Establish claim-type standards: what requires a named source versus what can be stated as observed practice
- Build verification checkpoints into the production schedule, not just the final review
Research infrastructure is the foundation of E-E-A-T in AI search. Without it, trust signals vary by writer and by week.
Author and Reviewer Clarity Embedded in the Content System
Authorship and reviewer attribution are most valuable when they are systematic. A content system that applies SME review inconsistently produces uneven entity signals that retrieval systems cannot reliably weight.
- Every article should carry named authorship with documented credentials accessible to machines and humans
- Regulated or high-stakes claims require a named reviewer with verifiable qualifications
- Author schema should match across the article, the author bio page, and off-site profiles
- Review attribution should be visible within the article, not only in metadata
The goal is not to add an author’s name—it is to make the accountability chain machine-readable and consistent across every published page.
Technical Accessibility and Structural Formatting for Machine Parsing
Content that cannot be crawled, parsed, or loaded efficiently does not reach the retrieval pipeline. Beyond crawlability, structural formatting—headers, bullets, answer-first paragraphs, data tables—determines whether retrieval systems can identify the direct answer within a page.
- Page performance affects crawlability and machine accessibility, not just user experience
- Answer-first paragraph structure puts key evidence where retrieval systems are more likely to retrieve it
- Schema markup for authors, organizations, articles, and local entities improves entity recognition
- Clean HTML structure without excessive JavaScript-rendered content improves machine access
Technical infrastructure is not a separate SEO concern—it is part of the trust delivery mechanism for AI search.
How Content Ops Lab Builds Content Infrastructure
A 12-location regulated healthcare client needed to scale content production without creating compliance exposure or quality inconsistency. Over 23 months, Content Ops Lab built the system that made it possible—scaling from 10 articles per month to 50+ and delivering 1,000+ citation-verified articles with zero compliance issues.
The evidence:
- 23-month production track record in a regulated, multi-location environment
- 1,000+ citation-verified articles and pages delivered across dual-brand operations
- Zero compliance issues across the full production run in a regulated healthcare setting
- Scale from 10 to 50+ articles per month while maintaining verification and governance standards
- AI search traffic converted at 21.4% average over 8 months—6.4x the site average for the same client
- Citation verification is built into every production stage, not applied as a final editorial check
- Research-first workflow with documented source hierarchy and claim verification checkpoints
The Content Ops Lab Production System
Every article that leaves the Content Ops Lab system passes through the same verification and governance infrastructure. Trust is an output of the process, not a property of individual writers.
- Research: Source hierarchy applied before drafting; claims verified before content is written
- Verification: Every statistic, attribution, and claim is checked against primary documentation before production is complete
- Optimization: Structure, entity signals, and technical accessibility reviewed for machine parseability and answer-first clarity
- Delivery: Final QA against assignment standards, house style, and completeness before any article is published
Production infrastructure is what separates a content team that occasionally produces trustworthy content from one that produces it consistently at scale.
Ready to build a content infrastructure that scales without the compliance risk? Get in touch today — we’ll assess your current content operation and outline what a systematic approach would look like for your organization.
How Do You Measure E-E-A-T in AI Search Progress?
Measuring E-E-A-T in AI search means moving beyond rank tracking. The relevant signals are citations, referral quality, branded query presence, and conversion behavior—not a single dashboard number.
Citation Monitoring Across AI Platforms
Citation appearance in generative answers is the most direct evidence that AI systems are retrieving and trusting your content. Monitoring requires systematic prompt testing across platforms—Google AI Overviews, ChatGPT, Perplexity, Gemini—using queries aligned with your content topics, service areas, and entity coverage.
- Test branded queries to identify whether AI systems recognize your entity
- Test topic and service queries to identify which content is being cited versus excluded
- Track citation patterns across platforms—they do not surface identical source sets for identical queries
- Document citation frequency by content type to identify which trust signals are performing
Citation appearance is not a vanity metric—it reflects whether the content system is producing retrievable trust.
AI Referral Traffic and Conversion Quality
Traffic from AI search systems can be tracked as a referral channel, and conversion quality is the most commercially useful signal. A 12-location regulated healthcare client tracked AI search traffic, converting at an average of 21.4% over 8 months—6.4x the site average across other traffic sources.
- Monitor AI referral traffic as a distinct channel in analytics
- Measure conversion rates for AI-sourced traffic against the site average
- Use conversion quality as an indicator of citation relevance, not just volume
- Segment by content type to identify which article formats generate the most valuable AI referrals
Conversion quality answers what citation counts alone cannot: whether AI traffic is arriving from content that matches what users actually need.
Content QA as a Leading Indicator
Citation monitoring and referral tracking are lagging indicators. Content QA is the leading indicator—it tells you whether the production system is generating trust signals consistently before articles are published.
- Track citation verification completion rates across the content pipeline
- Monitor author and reviewer attribution consistency across published articles
- Audit entity consistency for practitioners, locations, and services on a set schedule
- Use technical performance reviews to catch accessibility issues before they affect crawlability
AI search measurement is not one report. It is a monitoring system across visibility, citation quality, referral behavior, and production QA.
Key Takeaways
- E-E-A-T in AI search is not a direct ranking formula, but the trust qualities it describes—verifiability, authorship clarity, accurate sourcing, and entity consistency—directly affect whether AI systems retrieve, use, and cite your content.
- AI search functions as a trust-screening environment: generative answers cite a small number of sources, and content that cannot be verified, parsed, or attributed may never enter the answer pipeline.
- Trust must be built into the production system, not added during editing; brands that treat E-E-A-T as page-level polish will produce inconsistent trust signals that compound in scale.
- Multi-location brands face a compounding problem: every location, practitioner, service description, and local entity must produce consistent trust signals, or weak points undermine the domain’s overall profile.
- A 12-location regulated healthcare client operated at 50+ articles per month with zero compliance issues and 1,000+ citation-verified articles over 23 months—proof that trust infrastructure is a production problem, not a copyediting problem.
- AI referral traffic converted at 21.4% over 8 months—6.4x the site average—demonstrating that AI search visibility, when earned through content infrastructure, produces commercially meaningful results.
- The next competitive advantage is not more content; it is a verified, structured, scalable content operation that makes trust visible, repeatable, and machine-readable across every published article.
Frequently Asked Questions About E-E-A-T in AI Search
Does E-E-A-T directly determine whether AI search systems cite your content?
Not as a documented direct factor. No major AI platform has publicly identified E-E-A-T as a named citation framework. What is documented is that AI retrieval systems prioritize reliable, well-sourced, clearly attributed content. The trust qualities E-E-A-T describes are the same qualities retrieval systems need to confidently select and synthesize a source, making the underlying infrastructure requirements identical.
What is the first step in building E-E-A-T into a content operation?
Start with verification standards, not publishing volume. Establish a documented source hierarchy, define which claim categories require primary source verification, and build citation checkpoints into the workflow. Standardize author and reviewer attribution across all content. Audit entity consistency—how practitioners, locations, and services are described—before replicating it across new pages at scale.
Why does E-E-A-T matter more for healthcare, legal, and financial content?
Regulated content is subject to higher trust requirements from both search systems and users. Google’s quality rater guidelines identify YMYL content as subject to more rigorous quality evaluation, and AI systems that ground medical or legal answers face greater pressure for accuracy because errors can cause real harm. Verified practitioner credentials, named reviewers, and compliant language are the minimum threshold for retrieval eligibility in these categories.
Can a smaller competitor out-cite a larger brand in AI search?
Yes, in specific query contexts. When a smaller brand provides clearer, more complete, better-sourced content for a specific question, retrieval systems can select it over a larger brand’s more authoritative but less structured page. Third-party industry analysis suggests that trust signal quality can outperform ranking position in predicting AI citation frequency. Domain authority matters, but it is less deterministic in AI retrieval than in traditional ranking.
How does Content Ops Lab help brands build E-E-A-T into content production?
Content Ops Lab builds research-first, citation-verified content systems for organizations that need scalable publishing without sacrificing trust, compliance, or brand consistency. The production system includes documented source hierarchies, citation verification at the drafting stage, author attribution standards, entity consistency protocols for multi-location environments, and structural formatting for machine parseability.
The Competitive Window on AI Search Trust Is Still Open
E-E-A-T in AI search did not become a secret ranking formula. It became more important because AI search changed the visibility environment around trustworthy content. Brands that understand that shift early are building the content infrastructure that earns AI citations. Brands that do not are producing volume without the underlying trust signals that retrieval systems need. “Google’s automated ranking systems are designed to prioritize helpful, reliable information that’s created to benefit people” — Google Search Central.
The brands that internalize that standard as an operating principle—not an editorial checklist—will show up in AI answers. Content Ops Lab has built the production system that makes the first outcome repeatable. The question is whether your operation is structured to do the same.