
Why Generic Content Fails in AI Search Even If It Ranks in Google
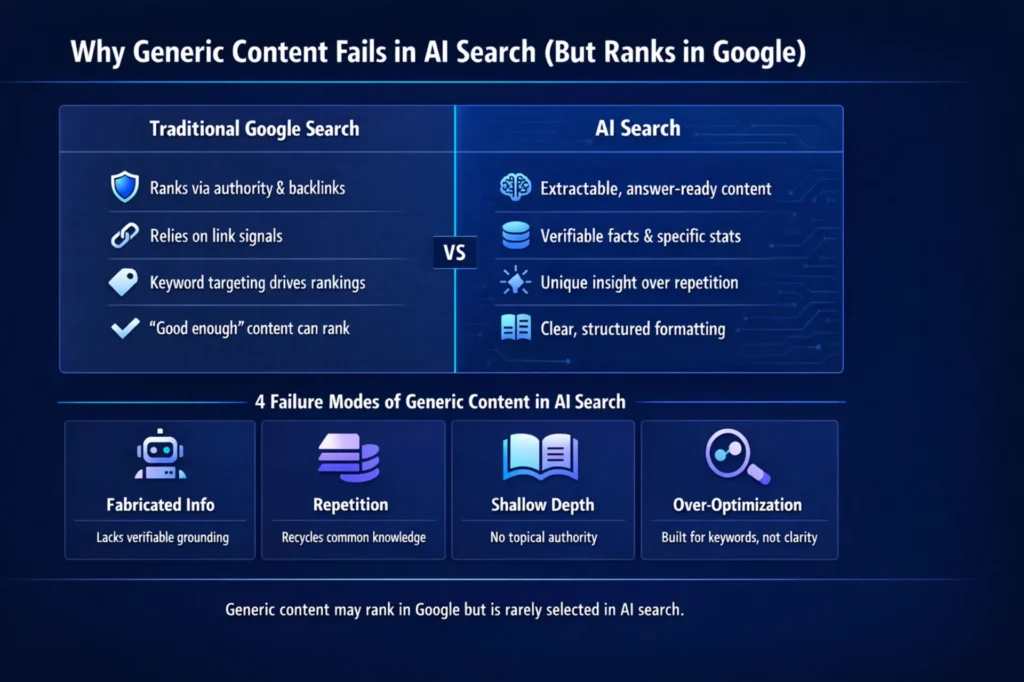
Why generic content fails in AI search, even if it ranks in Google, comes down to one structural gap: ranking systems and citation systems evaluate content by completely different criteria. ChatGPT, Perplexity, Claude, and Gemini don’t rank documents — they interpret them, extract structured answers, and select the most citation-worthy passages. As one analysis put it directly: “AI didn’t kill SEO. It killed average content. For decades, ‘good enough’ content worked… That era has ended.”
For VPs of Marketing running multi-location content operations at scale, this creates a measurable exposure: large content inventories holding organic rankings today while delivering zero AI citations and capturing none of the highest-converting traffic now flowing through those platforms.
Content Ops Lab built its verification infrastructure inside a live multi-location production environment — 1,000+ citation-verified articles delivered with zero compliance violations over 23 months, with AI search converting at 21.4% average CVR vs. a 3.32% site baseline.
The divergence between ranking and citation isn’t theoretical. It’s documented, measurable, and accelerating.
Related: SEO vs AEO vs GEO – How Multi-Location Businesses Should Think About Modern Search
What Is Generic Content, and Why Does It Explain Why Generic Content Fails in AI Search Even If It Ranks in Google?
Generic content is any content produced primarily to intercept keywords rather than provide decision-ready answers to specific user intent. It exists at scale because volume-first content strategies are operationally easier to execute than verification-first ones — and because traditional ranking signals have, until recently, rewarded the approach.
The Templated Production Trap
Most agencies and internal teams default to templated production because it’s the only way to hit volume targets without systematic infrastructure.
- Standardized outlines replicated across topics and locations
- AI prompts are generating nearly identical structure and phrasing
- Thin customization is limited to swapping city names or service terms
- No original research, data, or proprietary insight integrated
Google’s Search Quality Rater Guidelines now explicitly address this: raters are instructed that “if a search quality rater finds that a website is misusing AI to scale and create high quantities of low-effort and low-value content, then the rater should classify it as the ‘lowest’ quality.” The algorithmic consequences follow the rater signal.
How Semantic Sameness Gets Built Into Content Systems
When production systems rely on the same AI prompts to answer the same queries, output converges — not just structurally, but linguistically.
- Identical phrasing and topic sequencing across competing sites
- No differentiated data, examples, or original framing
- AI systems detecting pattern repetition at the domain scale
- Reduced citation probability when dozens of pages make identical claims
This is semantic sameness: content so interchangeable that AI engines have no reason to cite any individual instance. When a generative engine cross-verifies claims across sources, redundant coverage gets compressed. Citations consolidate around sources that offer something distinct.
Why Volume Strategies Create Compliance Exposure
For regulated industries, the templated production model introduces risk beyond poor AI visibility.
- Fabricated statistics cascade across dozens of location pages simultaneously
- No citation verification means no audit trail for compliance review
- AI-generated claims without source backing create legal exposure in healthcare and legal content
Generic content produced at volume isn’t just ineffective — in regulated industries, it’s a liability.
Why Does Generic Content Still Rank in Google Even When It Fails in AI Search?
Generic content still ranks because traditional ranking systems measure relevance and authority signals rather than reasoning depth or citation worthiness. Understanding why generic content fails in AI search, even if it ranks in Google, requires understanding how differently these two systems evaluate the same page.
Domain Authority as a Temporary Shield
Authoritative domains sustain rankings for relatively shallow content, particularly when backlink profiles and site history outweigh content-quality signals.
- Established domains carry historical performance and trust signals
- High-DA sites rank generic pages that a newer site could not
- Backlink profiles compensate for thin on-page content quality
- Authority is a finite buffer, not a durable strategy — and provides zero protection in AI search
How Traditional Ranking Signals Miss Depth
Classic ranking systems match documents to queries and order results by authority and relevance — not whether the content would hold up as a cited source.
- Keyword density, heading structure, and freshness signals were weighted heavily
- Off-page authority compensates for thin on-page substance
- Helpful Content system adds a quality signal, but it’s one factor among many
- Enforcement is uneven — borderline content on strong domains often survives
The Window Before Algorithmic Reclassification
Search Engine Land’s 16-month experiment on AI-generated content illustrates the pattern: “Only 3% of pages remained in the top 100, down from 28% in the first month.” Initial ranking happens quickly. Reclassification follows. Operators often build a strategy around early-window performance data — not the 12-month reality.
How Do AI Search Engines Actually Evaluate Content?
AI search engines don’t rank documents. They interpret them, extract structured information, cross-verify claims, and select the most citation-worthy passages. This is categorically different from how Google evaluates relevance — and it’s why content that passes a traditional SEO quality bar can still fail completely in AI search.
Extractability and Decision-Ready Answers
Generative engines need content they can convert directly into concise, actionable answers. Pages that cover topics broadly without stating explicit conclusions give AI systems almost nothing usable.
- Answer-first structure: direct response to the question in the opening 40-60 words
- Question-based headings that map to how users phrase AI queries
- Explicit recommendations rather than balanced hedging
- Logical flow that models can segment into distinct answerable units
GEOReport.ai captures the distinction: “ChatGPT, Claude, Gemini, and Perplexity don’t crawl pages the way search engines do; they interpret them.” Pages built around a clear question-answer architecture get cited. Pages without an extractable structure get forgotten.
Verification Standards in AI Citation Selection
AI systems are designed to provide verifiable answers with transparent citations — creating a structural bias toward content with documented, cross-checkable claims.
- Statistics backed by credible external sources are prioritized in citation selection
- Explicit source attribution increases citation probability
- Unsourced assertions deprioritized regardless of ranking position
- Claims that are cross-checkable across multiple domains carry more weight
When the web is saturated with generic, unsourced content, AI models increasingly rely on a small, stable set of trusted sources. Getting into that set requires substantiated content.
Structural Requirements for AI Parsing
- Descriptive headings and subheadings carrying a semantic signal
- Bullet lists and numbered steps are pullable as discrete units
- FAQ sections with direct answers optimized for conversational queries
- Schema markup exposing page structure programmatically
Content that buries key points in unstructured paragraphs or uses vague headings is harder to segment. Lower parseability means lower citation probability — even when the underlying content is accurate.
If your organization is publishing 20-50+ articles per month and hasn’t audited for AI citation readiness, you’re likely holding rankings while losing the conversion-driving traffic that AI search delivers. Content Ops Lab builds the infrastructure to close that gap. Contact us today to discuss your content production requirements.
What Does the Citation Data Show About Why Generic Content Fails in AI Search Even If It Ranks in Google?
The research on AI citation behavior is consistent across platforms: AI engines tend to consolidate around a small set of distinctive, verifiable, well-structured sources and largely ignore generic content — even content that holds organic rankings.
The Editorial Originality Gap
Search Engine Journal’s analysis of 4 million AI citations found that “original editorial content made up 81% of news citations in the dataset.” Syndicated, templated, and repurposed content barely registered.
- Original data, research, and expert commentary cited at disproportionate rates
- Templated content compressed or ignored across platforms
- Distinctive framing and proprietary insight create citation differentiation
- Named frameworks and authored methodologies increase attribution likelihood
Closing the editorial originality gap requires integrating genuine expertise and verified data into the production system — not just improving formatting.
Citation Consolidation and Volatility Patterns
BrightEdge’s citation volatility research reveals a pattern that should concern any operator managing a large content portfolio: “96.8% of cited domains saw zero change week over week. Among the roughly 3% that did move, 87% were declines.” Citations aren’t being redistributed to new winners. Lost citations disappear.
- A stable core of trusted citation sources forms and hardens over time
- Re-entry after losing citation status is difficult
- Early establishment in the cited set compounds — AI systems reinforce existing patterns
The citation hierarchy is solidifying now. Organizations that establish citation authority in the current window compound that advantage. Those who wait will find re-entry costly.
The Multi-Location Visibility Collapse
For multi-location businesses, the generic content problem compounds with scale. When location pages are templated and distinguishable only by city name, AI engines have no reason to recommend more than a fraction of the network — and inconsistency across pages can trigger domain-level deprioritization.
- Inconsistent NAP data signals instability to AI systems
- Templated pages provide no differentiated local signal
- Thin location coverage reduces domain association with topical expertise
- Verification inconsistency at scale undermines the entire portfolio’s citation credibility
Related: Answer Engine Optimization – What Multi-Location Operators Need to Know
Why Are Multi-Location Businesses Especially Exposed to This Shift?
Multi-location businesses face compounded AI search risk because their content model is structurally built for volume over differentiation. The same scaling decisions that made sense for traditional SEO — templated location pages, replicated service descriptions, standardized blog frameworks — actively undermine AI search visibility.
The Templated Location Page Problem
Search Engine Land’s 2026 AI local visibility report puts the exposure in concrete terms: “AI assistants recommend only 1% to 11% of locations, revealing a massive gap between Google rankings and AI visibility.” For a 20-location network holding solid local pack rankings, AI systems may recommend 1-2 locations, often none.
- Templated pages are indistinguishable aside from city name swaps
- No differentiated service, specialty, or credential signals per location
- Generic content across locations gives AI systems no selection rationale
This is AI local visibility, which is up to 30x harder than ranking in Google.
AI Local Visibility vs. Google Local Rankings
The mechanisms AI systems use to select location recommendations differ from Google’s local ranking signals.
- AI systems favor pages with clearly articulated differentiators: services, specialties, verified credentials
- Consistent, structured NAP data is required across the entire network
- Q&A content addressing local-specific intents increases recommendation probability
- Review signals and structured schema improve location page extractability
A location ranking in the local pack, driven by proximity and backlinks, may still be invisible to an AI assistant tasked with recommending a specialist in that area.
How Inconsistent NAP Data Triggers AI Deprioritization
AI engines cross-verify information before citing or recommending. When a domain presents conflicting data — different phone numbers, address variants, inconsistent service descriptions — models may flag it as unstable and defer to brands with reliable, consistent facts.
- Address format inconsistencies signal data quality problems
- Phone number variants undermine trust in all location data
- Version drift between older and newer location pages compounds without systematic auditing
Citation credibility is a network-level problem, not a page-level one.
What Does It Take to Build Content That Earns AI Citations at Scale?
Building content that earns AI citations at scale requires systematic infrastructure, not better prompts. The gap between generic and citation-worthy content isn’t about individual article quality — it’s about the production system generating them.
The Four Dimensions of Citation-Worthy Content
Research across BrightEdge, Search Engine Journal, and GEO frameworks identifies four consistent characteristics of AI-cited content.
- Originality: Distinctive contributions — original data, first-hand experience, expert commentary — rather than consensus rephrasing
- Verifiability: Explicit statistics with source attribution, claims cross-checkable across multiple domains
- Structure: Answer-first formatting, question-based headings, bullet-heavy architecture, and FAQ sections optimized for extraction
- Authority: Consistent topical depth across the site, not isolated high-quality posts surrounded by thin content
Verification Infrastructure for Large Content Portfolios
Large sites need internal verification infrastructure to remain attractive to AI engines — version control for key facts, documented sources for statistics, processes for auditing conflicting claims.
- Systematic citation tracking prevents hallucinated statistics from entering the portfolio
- STAT vs. CLAIM labeling creates different verification standards for different evidence types
- Audit trails enable compliance review and citation accuracy defense
- Consistent data governance across location pages eliminates NAP inconsistency
Without verification infrastructure, scaling content production means scaling citation risk.
The First-Mover Advantage Window
The citation hierarchy is forming now. Industry observations suggest that fewer than 5% of multi-location healthcare practices actively optimize for AI search citations, and fewer than 10% of legal firms track AI referral traffic as a distinct conversion channel. Organizations building citation-worthy infrastructure now are establishing positions that will be costly for competitors to replicate once mainstream adoption accelerates.
Ready to build content infrastructure that earns AI citations — not just Google rankings? Get in touch today — we’ll assess your current content operation and identify where the citation gap is costing you conversions.
How Content Ops Lab Builds Content Infrastructure That Gets Cited
Content Ops Lab worked with a regulated multi-location organization that used this methodology to produce 1,000+ citation-verified articles over a 23-month production period — zero compliance violations, AI search converting at an average CVR of 21.4% vs. a 3.32% site baseline. That’s the production proof.
- 23-month production test inside a regulated multi-location organization — an active production environment, not a pilot
- 1,000+ citation-verified articles and pages with zero compliance violations across the full engagement
- 45% of all leads from organic search — outperforming paid search nearly 2:1 over a 6-month window
- AI search converting at 21.4% average CVR vs. 3.32% site baseline — 6.4x performance multiplier
- 887% ChatGPT traffic growth in 7 months (July 2025 – February 2026)
- 653% impression growth and 1,700% click growth for an emerging brand built from near-zero organic presence in 14 months
- 5x production scale — 10 articles/month to 50+ — without adding headcount
- Dual-brand methodology validated: same system applied to a mature brand and an emerging brand — both achieving 40-45% organic lead contribution
The Content Ops Lab Production System
- Research: Verified sources before generation — no AI writing from memory, no hallucinated citations
- Verification: Line-by-line citation cross-check with STAT vs. CLAIM labeling and full audit trail
- Optimization: Multi-platform architecture — Google + ChatGPT + Perplexity + Claude + Gemini simultaneously
- Delivery: WordPress staging or Google Docs — publish-ready, compliance-reviewed, Grammarly-verified
If your content operation generates volume without a verification infrastructure, you’re building citation risk into every article you publish.
FAQs About Why Generic Content Fails in AI Search
Can content rank in Google and still be invisible to AI search engines — and is this why generic content fails in AI search even if it ranks in Google?
Yes. Traditional ranking signals (domain authority, keyword relevance, backlinks) don’t predict the probability of AI citation. AI engines evaluate extractability, verifiability, and structural clarity — criteria that generic SEO content routinely fails. A page can hold a position-1 ranking while receiving zero AI citations.
How is an AI search citation different from a traditional ranking signal?
Ranking signals measure relevance relative to other documents. AI citation selection measures whether a page provides a decision-ready, extractable, verifiable answer to a specific query. A backlink from a high-authority domain improves rankings. It does not increase the likelihood that ChatGPT will cite your content. The evaluation mechanisms don’t overlap.
What does citation verification actually involve in a production content system?
Every statistic and claim is cross-checked against the source document before publication — exact quotes extracted, line numbers documented, STAT vs. CLAIM labels applied. It creates an audit trail for every data point in the portfolio. Without it, AI-generated content introduces hallucinated statistics at a rate proportional to the production volume.
How does this explain why generic content fails in AI search, even if it ranks in Google for multi-location businesses specifically?
Multi-location businesses are disproportionately exposed because their content model defaults to templated location pages distinguishable only by city name. AI assistants recommend only 1-11% of locations in local-intent queries. Templated networks give AI systems no selection rationale — and NAP inconsistencies across the network can trigger domain-level deprioritization, undermining even the locations with stronger individual content.
How does Content Ops Lab handle compliance requirements for regulated industries?
Every article is citation-verified against source research before publication. No claims are made from AI memory. The production system was built inside a regulated multi-location organization and delivered 1,000+ articles with zero compliance violations over 23 months. The verification infrastructure that produces citation-worthy content is also the one that produces compliance-ready content.
Key Takeaways
- Generic content can hold Google rankings through domain authority while delivering zero AI search citations — ranking and citation are two separate performance dimensions requiring separate evaluation
- AI engines evaluate extractability, verifiability, and structural clarity — not keyword relevance and backlink profiles — making traditional SEO quality bars insufficient for AI search performance
- 81% of AI news citations went to original editorial content; templated and syndicated content barely registered — rephrasing consensus instead of contributing original data is systematically deprioritized
- AI assistants recommend only 1-11% of locations in local-intent queries, making AI local visibility up to 30x harder than Google rankings — templated location pages make that gap worse
- 96.8% of cited domains see no week-over-week change, and losses dominate volatility — the citation hierarchy is forming now, and re-entry after losing position is difficult
- Less than 5% of multi-location healthcare practices are currently optimizing for AI search citation — the first-mover window is open, but measured in quarters
The Operator’s Path Forward on Why Generic Content Fails in AI Search
The data from 2023–2026 is consistent: AI search doesn’t penalize generic content the way Google’s spam updates do — it simply ignores it. Pages lacking extractable answers, verifiable claims, and clear information architecture don’t get demoted. They don’t register at all.
For multi-location operators managing large content portfolios, the question isn’t whether to build citation-worthy infrastructure — it’s how quickly the current approach is compounding a disadvantage in channels where high-intent users are now making decisions.
Content Ops Lab built its production system inside a live, regulated, multi-location environment and delivered 1,000+ citation-verified articles with zero compliance violations over 23 months. AI search traffic through that system converts at an average of 21.4% — 6.4x the site baseline.
The infrastructure that produces those results is what we build for operators who need content that performs well in both Google and AI search — without sacrificing scale or citation credibility.
Related: What Is Content Infrastructure for Multi-Location Brands?